
Really Simple Syndication (RSS) has been with us for a long time and allows us to see new articles on our favorite website easily. Python doesn’t have an RSS reader module in the standard library, so we’ll be using the Universal Feed Parser 5.1.3 to do our parsing. If you do not have it already, you should go download it from the Python Package Index now. We’ll use this blog’s RSS feed to make testing simpler. The url for the feed is: https://www.blog.pythonlibrary.org/feed/. During my experiments, I noticed that my blog software will change a dash into the following unicode character: \u2013. This will cause feedparser to throw a UnicodeEncodeError, so I also recommend downloading the handy unidecode module to help with that.
Getting Started
Once you have the prerequisites mentioned above, we can get started. The feedparser package is actually a single module and is pretty easy to use. Here’s a quick example:
import feedparser
rss = 'https://www.blog.pythonlibrary.org/feed/'
feed = feedparser.parse(rss)
for key in feed["entries"]:
print unidecode.unidecode(key["title"])
If you run this code it will print out the 10 latest article titles from the blog. If you are curious, try printing out the feed variable. If you do that, you will see a pretty gnarly dictionary that’s rather hard to follow. I ended up doing the following to make it a bit easier to read:
import pprint pp = pprint.PrettyPrinter(indent=4) pp.pprint(feed)
This will give you a print out that’s similar to the following snippet:
{ 'bozo': 0,
'encoding': u'UTF-8',
'entries': [ { 'author': u'Mike',
'author_detail': { 'name': u'Mike'},
'authors': [{ }],
'comments': u'https://www.blog.pythonlibrary.org/2014/01/03/reportlab-create-landscape-pages/#comments',
'content': [ { 'base': u'https://www.blog.pythonlibrary.org/feed/',
'language': None,
'type': u'text/html',
'guidislink': False,
'id': u'https://www.blog.pythonlibrary.org/?p=3639',
'link': u'https://www.blog.pythonlibrary.org/2014/01/03/reportlab-create-landscape-pages/',
'links': [ { 'href': u'https://www.blog.pythonlibrary.org/2014/01/03/reportlab-create-landscape-pages/',
'rel': u'alternate',
'type': u'text/html'}],
'published': u'Fri, 03 Jan 2014 22:54:11 +0000',
'published_parsed': time.struct_time(tm_year=2014, tm_mon=1, tm_mday=3, tm_hour=22, tm_min=54, tm_sec=11, tm_wday=4, tm_yday=3, tm_isdst=0),
'slash_comments': u'0',
'summary': u'The other day I had an interesting task I needed to complete with Reportlab. I needed to create a PDF in landscape orientation that had to be rotated 90 degrees when I saved it. To make it easier to lay out the document, I created a class with a flag that allows me to save […]
The post Reportlab: How to Create Landscape Pages appeared first on The Mouse Vs. The Python.
',
'summary_detail': { 'base': u'https://www.blog.pythonlibrary.org/feed/',
'language': None,
'type': u'text/html',
'value': u'The other day I had an interesting task I needed to complete with Reportlab. I needed to create a PDF in landscape orientation that had to be rotated 90 degrees when I saved it. To make it easier to lay out the document, I created a class with a flag that allows me to save […]
The post Reportlab: How to Create Landscape Pages appeared first on The Mouse Vs. The Python.
'},
'tags': [ { 'label': None,
'scheme': None,
'term': u'Cross-Platform'},
{ 'label': None,
'scheme': None,
'term': u'Python'},
{ 'label': None,
'scheme': None,
'term': u'Reportlab'}],
'title': u'Reportlab: How to Create Landscape Pages',
'title_detail': { 'base': u'https://www.blog.pythonlibrary.org/feed/',
'language': None,
'type': u'text/plain',
'value': u'Reportlab: How to Create Landscape Pages'},
'wfw_commentrss': u'https://www.blog.pythonlibrary.org/2014/01/03/reportlab-create-landscape-pages/feed/'},
I shortened that up quite a bit as you get a LOT of detail. Anyway, back to parsing the feed dict. If you print out the keys, you’ll see they are as follows: feed, status, updated, updated_parsed, encoding, bozo, headers, href, version, entries, namespaces. The one I think is probably the most useful is the entries key. If you access its value, you will find a list of dictionaries that contain information about each of the ten articles.
Of course, this isn’t very interesting if we don’t have a nice way to display the data. Let’s take a moment and create a simple user interface using wxPython!
Creating the UI
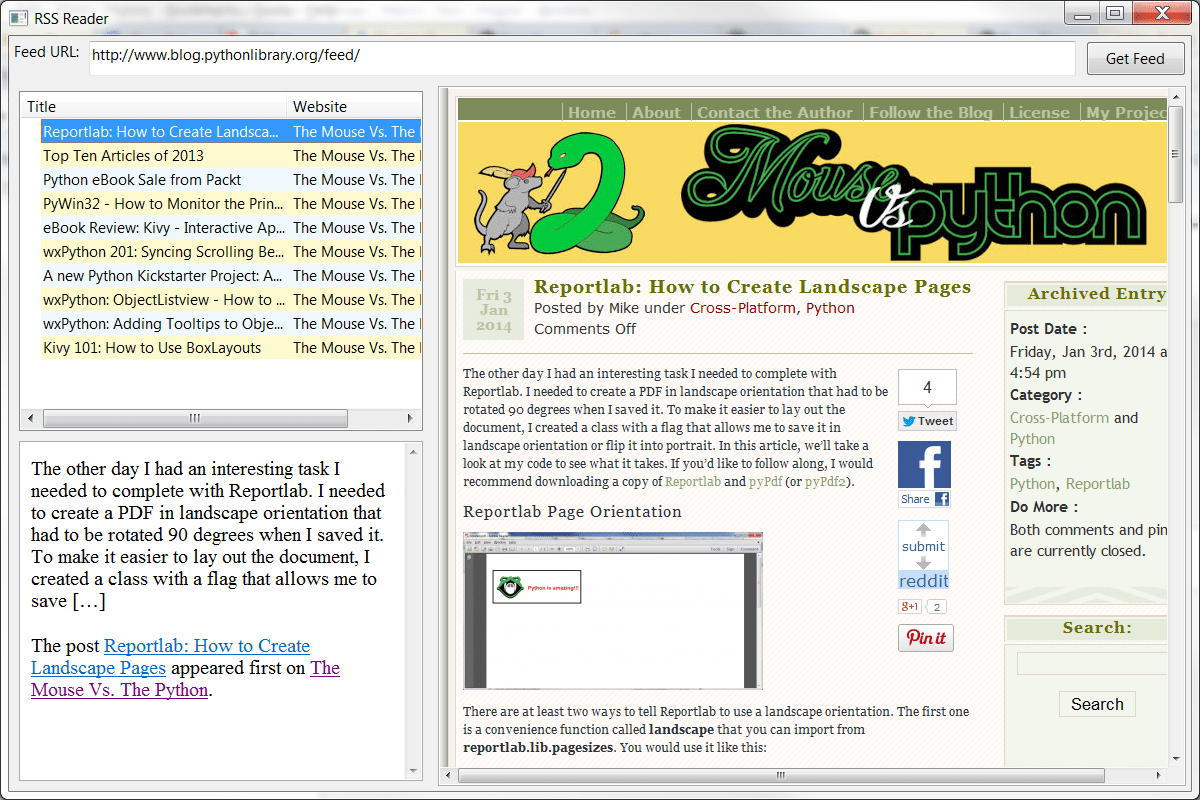
I recommend using wxPython 2.9 or higher for this next piece as the WebView widget was added in that series and that makes displaying HTML much simpler. I’ll be using wxPython 2.9.4 (classic). I’m also going to use ObjectListView, so make sure you have the right packages install before you try to do this exercise. Let’s jump right into the code!
# wxRss.py
import feedparser
import os
import unidecode
import wx
import wx.html2 as webview
from ObjectListView import ObjectListView, ColumnDefn
########################################################################
class RSS(object):
"""
RSS object
"""
#----------------------------------------------------------------------
def __init__(self, title, link, website, summary, all_data):
"""Constructor"""
self.title = title
self.link = link
self.all_data = all_data
self.website = website
self.summary = summary
########################################################################
class RssPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent, style=wx.NO_FULL_REPAINT_ON_RESIZE)
self.data = []
lbl = wx.StaticText(self, label="Feed URL:")
self.rssUrlTxt = wx.TextCtrl(self, value="https://www.blog.pythonlibrary.org/feed/")
urlBtn = wx.Button(self, label="Get Feed")
urlBtn.Bind(wx.EVT_BUTTON, self.get_data)
self.rssOlv = ObjectListView(self,
style=wx.LC_REPORT|wx.SUNKEN_BORDER)
self.rssOlv.SetEmptyListMsg("No data")
self.rssOlv.Bind(wx.EVT_LIST_ITEM_SELECTED, self.on_select)
self.rssOlv.Bind(wx.EVT_LIST_ITEM_ACTIVATED, self.on_double_click)
self.summaryTxt = webview.WebView.New(self)
self.wv = webview.WebView.New(self)
# add sizers
rowSizer = wx.BoxSizer(wx.HORIZONTAL)
rowSizer.Add(lbl, 0, wx.ALL, 5)
rowSizer.Add(self.rssUrlTxt, 1, wx.EXPAND|wx.ALL, 5)
rowSizer.Add(urlBtn, 0, wx.ALL, 5)
vSizer = wx.BoxSizer(wx.VERTICAL)
vSizer.Add(self.rssOlv, 1, wx.EXPAND|wx.ALL, 5)
vSizer.Add(self.summaryTxt, 1, wx.EXPAND|wx.ALL, 5)
dispSizer = wx.BoxSizer(wx.HORIZONTAL)
dispSizer.Add(vSizer, 1, wx.EXPAND|wx.ALL, 5)
dispSizer.Add(self.wv, 2, wx.EXPAND|wx.ALL, 5)
mainSizer = wx.BoxSizer(wx.VERTICAL)
mainSizer.Add(rowSizer, 0, wx.EXPAND)
mainSizer.Add(dispSizer, 1, wx.EXPAND)
self.SetSizer(mainSizer)
self.update_display()
#----------------------------------------------------------------------
def get_data(self, event):
"""
Get RSS feed and add it to display
"""
msg = "Processing feed..."
busyDlg = wx.BusyInfo(msg)
rss = self.rssUrlTxt.GetValue()
feed = feedparser.parse(rss)
website = feed["feed"]["title"]
for key in feed["entries"]:
title = unidecode.unidecode(key["title"])
link = key["link"]
summary = key["summary"]
self.data.append(RSS(title, link, website, summary, key))
busyDlg = None
self.update_display()
#----------------------------------------------------------------------
def on_double_click(self, event):
"""
Load the selected link in the browser widget
"""
obj = self.rssOlv.GetSelectedObject()
self.wv.LoadURL(obj.link)
#----------------------------------------------------------------------
def on_select(self, event):
"""
Load the summary in the text control
"""
base_path = os.path.dirname(os.path.abspath(__file__))
obj = self.rssOlv.GetSelectedObject()
html = "%s" % obj.summary
fname = "summary.html"
full_path = os.path.join(base_path, fname)
try:
with open(full_path, "w") as fh:
fh.write(html)
print "file:///" + full_path
self.summaryTxt.LoadURL("file:///" + full_path)
except (OSError, IOError):
print "Error writing html summary"
#----------------------------------------------------------------------
def update_display(self):
"""
Update the RSS feed display
"""
self.rssOlv.SetColumns([
ColumnDefn("Title", "left", 200, "title"),
ColumnDefn("Website", "left", 200, "website"),
])
self.rssOlv.SetObjects(self.data)
########################################################################
class RssFrame(wx.Frame):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, title="RSS Reader", size=(1200,800))
panel = RssPanel(self)
self.Show()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = wx.App(False)
frame = RssFrame()
app.MainLoop()
This code is a little complicated, so let’s spend some time figuring out what’s going on here. Along the top of the application, we have a label, a text control and a button. The text control is for adding RSS feed URLs. Once added, you click the button to retrieve the RSS feed. This happens by calling the get_data event handler. In said handler, we show a BusyInfo dialog that tells the user something is happening while we parse the feed. When the parsing is done, we dismiss the dialog and update the display.
If you select an item from the ObjectListView widget on the left, then you will see a summary of the article below. That bottom left widget is a small example of the WebView widget. It is basically a fully fledged web browser, so if you click a link, it will attempt to load it. You will notice that in that selection event handler, we actually save the HTML to a file and then load it into the WebView widget.
To actually view the entire article, you can double-click the item and it will load on the right in another WebView widget.
Wrapping Up
Wasn’t that fun? I thought it was. Anyway, at this point you should know enough to parse an RSS feed with Python and actually create something halfway useful to boot. Here are some improvement ideas:
- add a way to save the feed data so you don’t have to parse it every time you start the program
- create a way to save the articles you like
- hide the articles you read, but also add a filter to show just the read articles or maybe all the articles
Creating applications like this always sets my imagination in motion. I hope it does the same for you. Have fun and happy coding!
Related Links
- Feedparser documentation
- BlizzPodcastRSS – an interesting set of examples demonstrating various ways to use feedparser
Pingback: wxPython: Creating a Simple RSS Reader | Hello Linux
Pingback: A reply to « wxPython: Creating a Simple RSS Reader » | FoxMaSk - Le Free de la passion
Hi, Mike:
I’m new to Python, so I appreciate simple little tutorials like this.
Quick question: for some reason my code is tripping over the “get_data” function. When I press the “Get Feed” button, it throws the following error:
Traceback (most recent call last):
File “D:DropboxwxRss.py”, line 68, in get_data
self.data.append(RSS(title, link, website, summary, key))
NameError: global name ‘RSS’ is not defined
I fiddled with it a little, changing “RSS” to lower case and trying to “append” without the “RSS” and other such randomness, but I’m stumped. Forgive my n00bness if it’s something obvious I’m overlooking..
Hi Rob,
I tried copying the code onto another machine and it worked for me. Make sure you copied the code in its entirety. For example, do you have the RSS class code copied?
– Mike
That was it! Thank you. Don’t know how I missed that one.
Pingback: A Snake, a Rodent and an Epiphany | My Python Adventure
Pingback: Leaps and Bounds | My Python Adventure