
Using Asyncio and Batch APIs for Remote Services
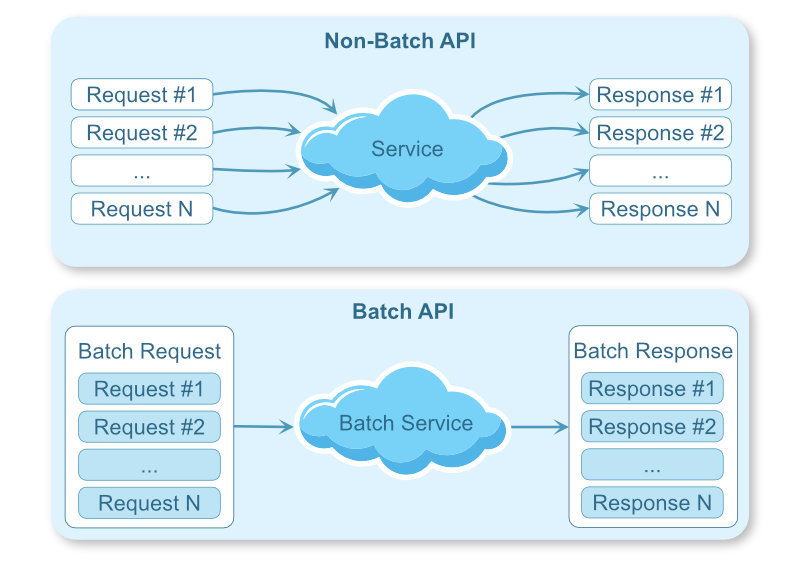
Introduction to Batch APIs In modern Python applications, it’s common to access remote API using REST or other web-based technologies. Batch APIs are capable of processing multiple requests with a single call. You can use batch APIs to reduce the number of network calls to the remote service. This is ideal when you have to […]
Using Asyncio and Batch APIs for Remote Services Read More »